Y型(星型)和(三角形)是指电机绕组的连接方式,两者在结构上有所区别,对于异步电动机而言,在启动阶段通常会采用星型连接方式,带电机成功启动后,则转换话三角形连接,一次达到减少启动电流,减轻电网冲击的效果,这种启动技术被称为星三角降压启动
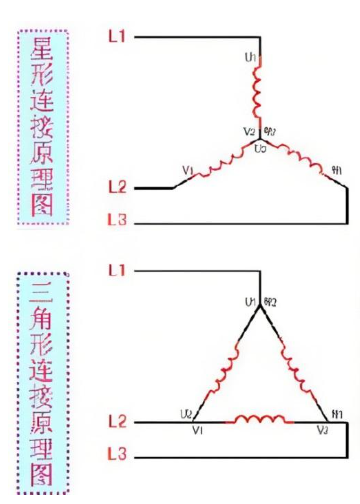
在用桥路测试仪器测量的时候,星型接法得除以2,三角形接法不用
在星型接法中,线电压是相电压的sqrt(3)倍,而线电流等同于相电流。
三角形接法中,线电压等于相电压,线电流则是相电流的sqrt(3)倍。
所以当电机采用星型接法的时候线圈电压是为220V,运行电流为相电流,较小;电机采用三角形接法的时候,线圈电压为380V,运行电流为相电流的根号三倍,较大。
当电机从静止启动时,星型接法的启动转矩仅是三角形接法的一半,启动电流仅仅是三角形启动的三分之一左右,三角形接法启动时启动电流时额定电流的4-7倍,启动转矩大。